The legal sector is particularly affected by the upheavals brought about by the major AI language models (LLMs) in various business areas. Three examples will illustrate low-threshold opportunities for the implementation of AI in law firms.
Overview, what happened so far
Some readers might remember the story from 5 months ago when I reported on a “hostile” mandate takeover by ChatGPT. A lot has happened since then.
Just one day before the publication of this article on December 6, 2023, Google introduced its latest multimodal model “Gemini.” In its most powerful form, it is said to surpass 90% of all experts in nearly 60 areas in knowledge and problem-solving competence!
Savor this statement from the Gemini presentation:
With a score of 90.0%, Gemini Ultra is the first model to outperform human experts on MMLU (massive multitask language understanding), which uses a combination of 57 subjects such as math, physics, history, law, medicine and ethics for testing both world knowledge and problem-solving abilities.
https://blog.google/technology/ai/google-gemini-ai/#performance
Even though it’s difficult to get used to such superlative news, it is all the more important to roll out and utilize business applications for the core legal professions of lawyers, judges, state attorneys and notaries. The working world in these areas will change significantly. The sooner the transformation begins in businesses and law firms, the fewer reservations and surprises there will be.

Three Examples
Therefore, I would like to illustrate the possibilities that already exist with very manageable effort to implement artificial intelligence in an average law firm, using three examples.
In the selected examples, compliance with professional regulations and the data protection framework of the GDPR is the main focus. None of the presented solutions and/or companies has an economic close relationship to the author.
- Speech to text
Who doesn’t know the struggle with digital dictation and its various helpers, which sometimes transcribe better, sometimes worse. None of the colleagues I know have ever really used one of the existing solutions sustainably. Whether it’s saving the trouble of writing a memo after a meeting, or simply dictating correspondence or legal documents without having to cater to the specific needs of the software – as was the case with the good old tape machines. It could be so simple.
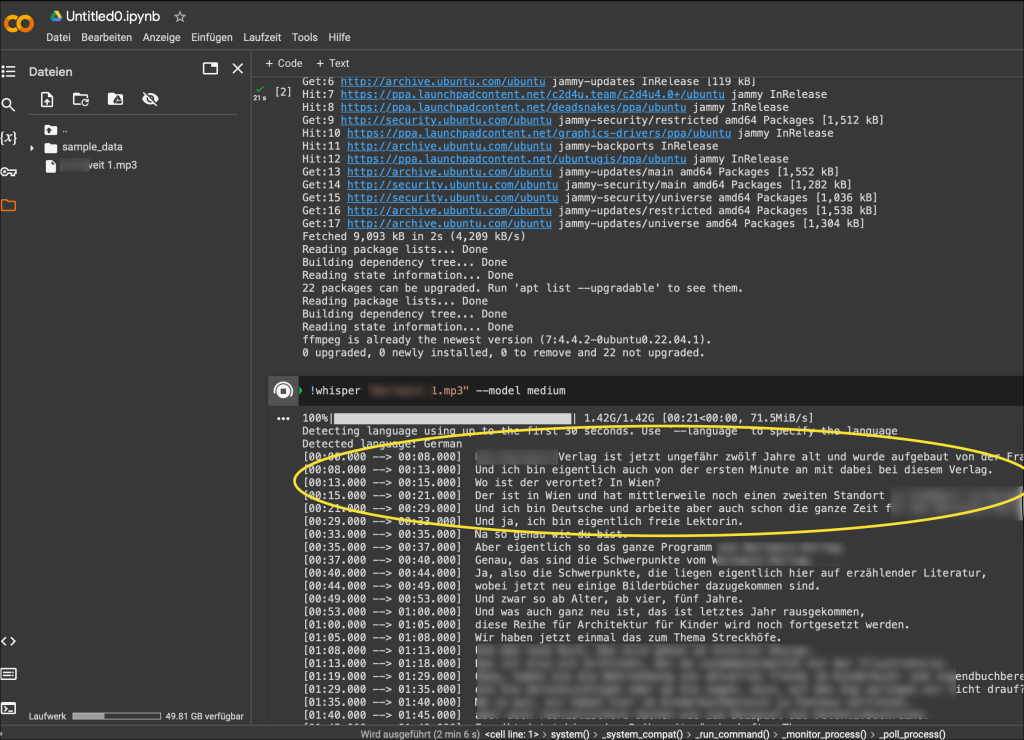
With “Whisper,” Open AI (the company behind ChatGPT) introduced a model for transcribing audio files some time ago. The neural networks are open source and can be operated either through a software interface, in Google Drive, or locally. The model can transcribe nearly 100 languages and remarkably ignores background noise.
On Apple Macs, there is already a completely locally operating software solution called MacWhisper, which offers great functionality even in the free version.
Listen to the original audio source (a 2 person interview) with significant background noise in an excerpt here:
The model can also be tested “risk-free” (as depicted here) in the Google Drive using the Colaboratory plugin in a GPU environment.
Transferring a 5-minute file takes less than 3 minutes, including the implementation of the model in the GPU environment on Google Drive.
Internally in our law firm, we also transcribed a file with a duration of 1 hour and 26 minutes in Portuguese (lecture) and managed to do it de facto error-free in just under 20 minutes.
Instructions for local and Google Drive installation can be found here:
MacWhisper can be downloaded here (without subscription):
https://goodsnooze.gumroad.com/l/macwhisper
In the Apple App Store, there is only a subscription version available.
Also of interest could be the application for the always tight judicial budget. In criminal proceedings, hearings are already being filmed. The audio track can simply be used to create a rough draft of a transcript with Whisper, entirely without human effort. The same applies to civil proceedings.
- AI Document Search for Legal Users
For law firms, document search is a particular challenge. The less structured (by which I mean not a typical lawyer’s software file) the data is stored, the harder it is to find relevant information.
Even conventional indexing methods often only offer moderate search success. Moreover, SharePoint solutions are often complex. They come with high licensing and maintenance costs and are therefore not an option for many.
A more recent, dynamic, and very accessible solution is offered by the Munich software company Curiosity.ai with the Curiosity App for Windows, Mac, and Linux. Of course, the apps run entirely locally. Data is not transmitted to Curiosity.

In addition to the classic indexing for extensive documents and collections in network structures, the search offers an in-house AI search mode, which improves the hit rate and provides context-based results using a neural model.
Integration of cloud services and email services is possible.
The Curiosity App also has an interface to the middle model of Whisper, which allows for the transcription of audio files within the software (see above in the “Speech to Text” section).
Those who want to fully exploit the potential of artificial intelligence in their work with the Curiosity App can optionally integrate ChatGPT 3.5 into the service. This provides the ability to create pre-made response emails by AI, ask specific questions about a particular problem to a search index, and much more, already familiar from the use of ChatGPT. The small but significant difference being that here, your own document collection is used for answering.
However, with this latter option, data must still (for now) be transmitted to OpenAI for the preparation of responses, which according to Curiosity, are deleted after 30 days.
Solution – Assistants API?
Particularly interesting in this context is the announcement by OpenAI of the Assistants API (Application Programming Interface), which allows the use of ChatGPT 4 in one’s own applications. Here, content can be processed locally without data transmission. Of course, in such a scenario, significant computing capacities should be provided to avoid disappointment due to slow responses from the beginning.
Curiosity is available for free testing here:
- Your Own Law Firm Chatbot – Playground for the Experimentally Inclined
Those who want to create their own law firm or lawyer chatbot with their own data, independent of software providers, also have many possibilities.
Program codes like the enormously popular PrivateGPT or localGPT on Github can provide a ChatGPT-like problem-solving instance in the law firm with their own text content. This way, you chat with your own documents.
Many open-source models such as LLAMA from META or Huggingface can be used for this purpose.
LocalGPT can also be operated with a completely German-speaking model named LeoLM, so that the input and output do not have to be switched from English to German.
The installation requires basic knowledge of the command shell (terminal) and web servers but should be implementable with some patience by a talented IT specialist or hobbyist IT and lawyer in personal union (like myself).

If you are hesitant about such an installation, you can create a model yourself at OpenAI’s Playground. For example, you can assign it the task of a legally trained office staff member who will assist you in research and problem-solving using the provided documents, or even prepare a legal document for the court.
However, this pleasure is not free. You have to buy tokens from OpenAI in advance for the content generated, which you can use up in large quantities or until the set limit during such play.
Outlook
It will take a few more years before clients increasingly turn to the services of language models specialized in law, which, with the help of existing legal databases, will be able to handle significant parts of legal professional work. If you, like me, have taken a look at the video linked below, it will quickly become clear that the potential is enormous. Until then, this potential shall be deployed in legal business applications reasonably. I will continue to stay involved.